
- Sky
- Blueberry
- Slate
- Blackcurrant
- Watermelon
- Strawberry
- Orange
- Banana
- Apple
- Emerald
- Chocolate
- Charcoal


Adorable-Catgirl
-
Content Count
44 -
Joined
-
Last visited
-
Days Won
9
Posts posted by Adorable-Catgirl
-
-
uncpio is a rather simple binary CPIO extractor (File begins with 0x71C7 or 0xC771, made with cpio -oHbin). To acquire uncpio, run
pastebin get YbrVjRwa /bin/uncpio.lua
To use, make the directory you'll be extracting your CPIO archive to, cd into it, then run
uncpio path/to/your/file.cpio
And it will extract to the current directory. Currently only works in OpenOS, as far as I know.

- Izaya and Fingercomp
-
 2
2
-
Fair. Also, we could use binary CPIO for bootable packages. That would probably be the best bet. It's standard and been around for a while.
Also, OEFI v2 applications should end in `.efi2` to differentiate them from the OEFI v1 applications. OEFI v2 applications should also probably support a few basic arguments.
-
So, some recommendations for OEFI v2:
- Storage of addresses in a binary format
- Maybe a standard set of commands for an OEFI shell?
- "oefi.loadfile(path)", which loads a file from the boot device
- Vendor prefixes on extensions to OEFI (ie "oefi.vendor.extensionmethod()")
- BIOS configuration space of 64 bytes, at the end of the EEPROM
- Maybe a network boot protocol?
- The OEFI library should be global unless booting in compatibility mode (for example, from an init.lua file)
- OEFI implementation must allow the OS to return
- Standard for passing kernel arguments (For things like Fuchas NT or Tsuki)
- Maybe a sample OEFI implementation?
- Must support compatibility mode, though maybe there can be an option to disable compatibility mode.
- Maybe a URF-based bootable package?
-
(Shoot me if this is a necropost)
Zorya has been updated! It now has a new, fancy installer that may still be visually buggy. It installs Zorya fine enough though. (And I plan to use it for my OS's installer.)
Zorya 1.0 adds a few new features:
- OEFI support
- A new `zorya` library
- General improvements over 0.1. It's a feature, trust me.
-
I'm using ocvm. I mainly use it because OCEmu has some weird issues, though ocvm seems to have some strange issues too.
-
I was thinking about component IDs. Shouldn't they be minified? Like, "68ca0f59-ac2c-49f8-ba6a-3c4c7e5f069b" turns into a string of 16 bytes:
{0x68, 0xCA, 0x0F, 0x59, 0xAC, 0x2C, 0x49, 0xF8, 0xBA, 0x6A, 0x3C, 0x4C, 0x7E, 0x5F, 0x06, 0x9B}
Also, OEFI implementations need to have room for custom configuration, as something like Zorya needs some EEPROM space for knowing the device that the "zorya-module" and "zorya-cfg" folders are stored on. Maybe 64 bytes or so can be dedicated to custom config? 64 bytes should be plenty of space for basic configuration, yeah? 32 bytes would be too little, probably, as a component ID can only be shrunk down to 16 bytes.
As for how to convert binary component ID to text component ID and back again:
function binid_to_hexid(id) local f, r = string.format, string.rep return f(f("%s-%s%s", r("%.2x", 4), r("%.2x%.2x-", 3), r("%.2x", 6)), id:byte(1, 16)) end function hexid_to_binid(id) local lasthex = 0 local match = "" local bstr = "" for i=1, 16 do match, lasthex = id:match("%x%x", lasthex) bstr = bstr .. string.char(tostring(match, 16)) end return bstr end
Otherwise, this looks pretty good.
-
Also, I plan on adding DEFLATE support for URF and support for PolarisFS (From an OS I'm working on, Tsuki) if/when I get the chance.
-
Sorry about that, haha. Feels free to help revise it. I just haven't worked on any OC stuff in a while.
-
Ay, so I made a Zorya module for booting Fuchas.
Pastebin is 3gpLaRpq
Currently, it doesn't support passing arguments. It shouldn't be hard to add that, though.
-
Yea, no problem. I'll also probably add the option to make the zorya-modules and zorya-config folders part of the normal filesystem. Might change how Zorya stores options to specify if it should download the modules or load them from the github repo. But I'll have to test that on my PC since OCEmu locks up when I try to fetch things from HTTPS

-
Ah, I see. I'll probably combine a few of the files together, yeah. I do want to still have it load modules from zorya-modules, just to make it simple to drop a loader in.
I have some things to add and fix for Zorya 0.2 but I'll do that for the next release.
-
Ah, I would, but I wanted to make the BIOS simple to extend (and patch).
-
this is just a draft, feel free to suggest whatever.
URF v1.1
Abstract
This document describes the URF, intended to make mass file exchange easier.
Rationale
There are many competing methods of exchanging large amounts of files, and many are incomplete, such as TAR implementations, or proprietary, such as NeoPAKv1. With this in mind, a standard format will make file exchange less error prone.
Conventions
The key words "MUST", "MUST NOT", "REQUIRED", "SHALL", "SHALL NOT", "SHOULD", "SHOULD NOT", "RECOMMENDED", "MAY", and "OPTIONAL" in this document are to be interpreted as described in RFC 2119.
All strings are encoded with UTF-8, prepended with an ALI corresponding to the length of the string in bytes.
Character specifications such as
NULLandDC1are part of US ASCII, unless otherwise specified.Concepts
- Signature: Data at the beginning of the File, marking the File as a URF format archive, and specifying the version.
- File Table: Data structure containing all file information.
- Entry: Any data sub-structure in the File Table.
- Entry Specifier byte: A byte describing how to decode the data contained in an Entry.
- Object: A filesystem structure, i.e.. "file" or "directory".
- Attributes: Data describing the size, offset, parent Object, and Object ID of an Object.
- Extended Attributes: Data describing non-core attributes such as Permissions, Owner, Security, etc.
- Producer: A program or process that generates data in this format.
- Consumer: A program or process that consumes data in this format.
Arbitrary length integers
Arbitrary length integers (ALIs) MAY be over 64-bits in precision. ALIs are little endian. For each byte, add the value of the first seven bits, shifted by 7 times the number of characters currently read bits, to the the read value and repeat until the 8th bit is 0.
Signature
The Signature MUST be
URF(US-ASCII) followed by aDC1character, or an unsigned 32-bit little endian integer equal to 1431455249. The next two bytes MUST be the version number, the first being the major version, the second being the minor version. The next two bytes MUST beDC2followed by aNULLcharacter.File Table
The File Table MUST start after the Signature. This MUST contain all Entries, and MUST end with an EOH Entry. See EOH Entry.
Entry
An Entry MUST start with an Entry Specifier byte. The Entry Specifier byte MUST be followed with an ALI specifying the length. Data contained SHOULD be skipped if the Entry Specifier byte allows and the Entry Type is not understood.
Entry Specifier byte
An Entry Specifier byte MUST have the 7th bit set to 1. If the Consumer comes across an entry with the 7th bit not set to 1, the Consumer MUST stop reading the file and raise a fatal error. The 6th byte specifies if the entry is critical. The entry is critical if the 6th bit is set to 0. If the entry is critical and not understood, the Consumer should raise a fatal error; if the entry is non-critical, the Consumer SHOULD skip the entry and continue reading the file. If the 8th byte is set to 1, the Entry is a non-standard extension. Vendors MAY use this range for vendor-specific data.
Filesystem Structure
Any Object MUST have a Parent ID and an Object ID. Object ID 0 is reserved for the root directory.
File naming conventions
Object names MUST NOT contain any type of slash. Object names must also be of the 8.3 format, though the full name MAY be specified with Extended Attributes. Full names in Attributes MUST NOT contain any type of slash.
File offsets
File offsets are relative to the end of the File Table.
Entry Type: File
The Entry Specifier byte MUST be
F, and the data contained MUST be the name as a string, followed by the file offset and file size represented as an ALI, then followed by the Object ID, then Parent ID.Entry type: Directory
The Entry Specifier byte MUST be
D, and the data contained MUST be the name as a string, followed by the Object ID, then Parent ID.Entry type: Extended Attributes
The Entry Specifier byte MUST be
x, and the data contained MUST be the Object ID of the Entry the Entry is describing, followed by a four byte Attribute and the value.Currently recognized attributes include, names in US-ASCII:
-
NAME: The long name of the Object (String) -
PERM: The POSIX-compatible permissions of the Object (Unsigned 16-bit integer) -
W32P: Win32-compatible permissions of the Object, which override POSIX permissions (Unsigned 8-bit Integer, Read-Only [0x01], Hidden [0x02], System [0x04]) -
OTIM: Creation time of the Object (Unsigned 64-bit Integer) -
MTIM: Modification time of the Object (Unsigned 64-bit Integer) -
CTIM: Metadata update time of the Object (Unsigned 64-bit Integer -
ATIM: Access time of the Object (Unsigned 64-bit Integer) -
SCOS: Source OS of the Object (String)
Entry type: EOH
The Entry Specifier byte MUST be
Z, and the data contained MUST be the offset required to reach the end of the file.Compressed URF naming convention
In an environment with long names, the file extension SHOULD be
urffollowed by a period (.) and the compression method (i.e.gz,lzma,xz,deflate) In an environment with 8.3 names, the file extension MUST be one of the following:-
UMAfor LZMA -
UXZfor XZ -
UGZfor Gzip -
UL4for LZ4 -
UB2for BZip2
TODO
Document is incomplete. Document should outline how to build the Filesystem structure, etc. Document should be checked for clarity and rewritten if needed.
-
Zorya BIOS
Zorya BIOS is an extendable and configurable BIOS and bootloader, capable of booting any OS with the right extensions. It's similar to GRUB.
(sorry in advance for bios.lua)
All you need to install the BIOS is to flash bios.lua to a blank EEPROM, insert a blank floppy, then reboot. Note: This has only been tested on Tier 3 hardware and Lua 5.3. requires an Internet card.
PRs are welcome!
Future plans:
- Ability to load from non-managed disks (like disks formatted with msdosfs, etc)
- Make it easier to extend
- Clean up code!
- Ability to edit options from bootloader
- Automatically load an OS after n seconds
- MeltingBrain and Lizzian
-
 2
2


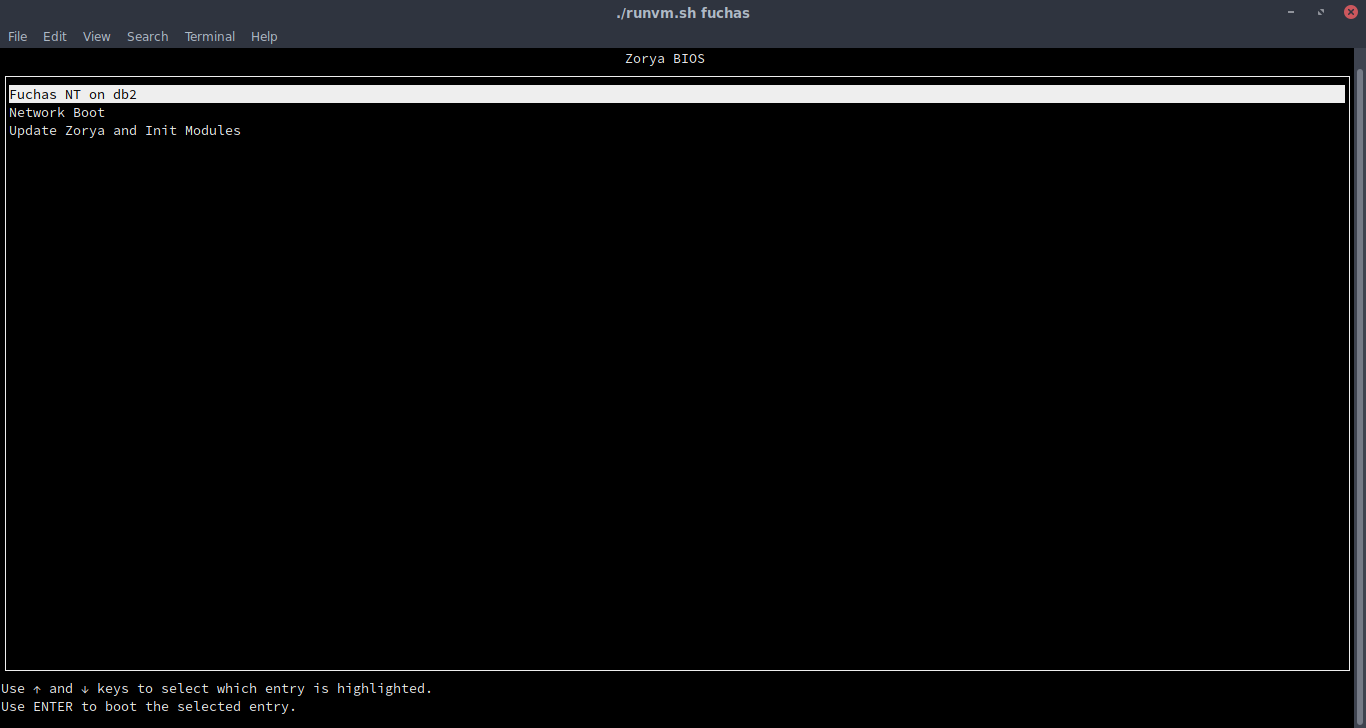
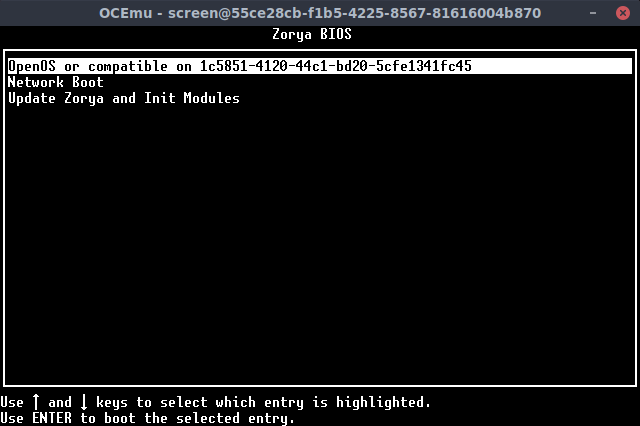
OETF #16 - Open Extensible Firmware Interface
in OpenEngineering Task Force
Posted
.efi2 could probably be a CPIO archive. Entry point can be defined by a .cfg file in the root of the archive. Or, we could also check if it's a CPIO file or a Lua file. Dunno, it's up to you.